文章来源:InnoDB Page Merging and Page Splitting
Kafka是什么?
Kafka是分布式、高吞吐、可扩展的实时数据流平台。
Kafka广泛使用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分。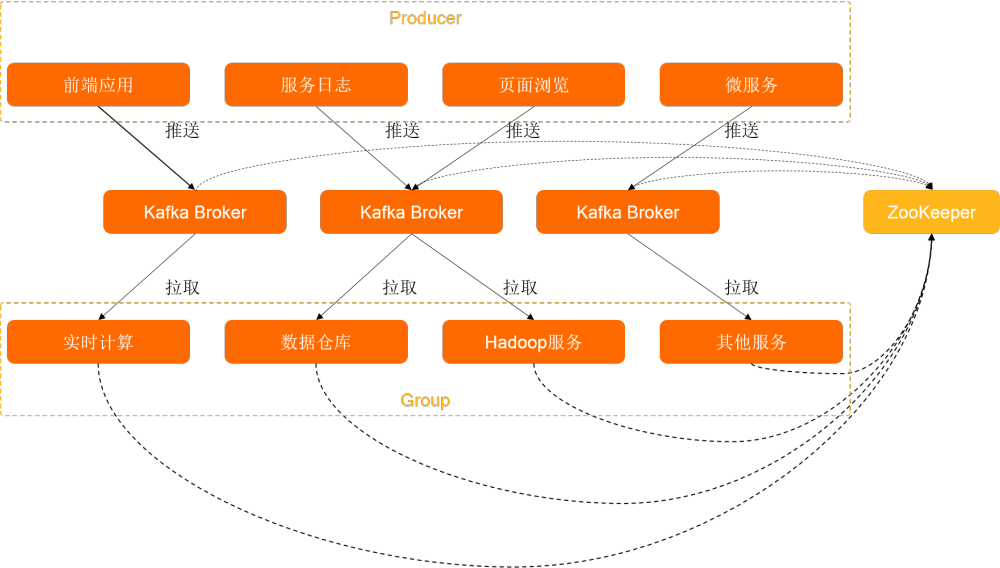
Producer:通过push模式向Kafka Broker发送消息。发送的消息可以是网站的页面访问、服务器日志,也可以是CPU和内存相关的系统资源信息。
Kafka Broker:用于存储消息的服务。Kafka Broker支持水平扩展。Kafka Broker节点的数量越多,集群的吞吐率(?)越高。
Group:通过pull模式从Kafka Broker订阅并消费消息。
Zookeeper:管理集群的配置、选举领导(Leader)分区,并且在Group发生变化时,进行负载均衡。
Kafka的特点
1. 优势
- 通信模式:支持队列和发布/订阅两种通信模式。(?)
- 高吞吐量、低延迟:在叫廉价的硬件上,Kafka也能做到每秒处理几十万条消息,延迟最低只有几毫秒。
- 持久性:Kafka可以将消息持久化到普通磁盘。
- 可扩展性:Kafka集群支持热扩展,可以动态向集群添加新节点。
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
2. 需要注意的问题
Topic/Partition过多,导致性能急速下降:KafkaTopic/Partition过多(如,对于普通磁盘,单机超过500个Topic/Partition),会导致存储碎片化,负载会发生明显彪高现象,Topic/Partition越多,则负载越高,发送消息响应时间越长。- 消息丢失:以下2种使用不当的场景,可能导致消息丢失,应根据业务场景避免。
- 生产消息:如果ack!=all或消息副本数不大于1,则Kafka Broker机器越长宕机时,可能导致消息丢失。
- 消费消息:消费端在未完全处理完消息时即提交offset,则在消费端异常时,可能导致部分消息丢失。
- 重复消费:生产者可能由于某种原因(如网络抖动或Kafka Broker宕机)没有接收到Kafka Broker的成功确认,然后重复发送消息,最终导致消费者接收到多个相同的业务消息。次场景需要消费者支持消息幂等性来解决。
- 消息乱序:Kafka只能保证同一分区内的消息有序,不同分区之间的消息不能保证有序。
- 不支持事务。
Kafka经典使用场景
- 大数据领域:网站行为分析、日志聚合、应用监控、流式数据处理、在线和离线数据分析等。
- 数据集成:将消息导入MaxCompute、OSS、RDS、Hadoop、HBase等离线数据仓库。
- 流式计算:与StreamCompute、E-MapReduce、Spark、Storm等流式计算引擎集成。
Kafka核心概念
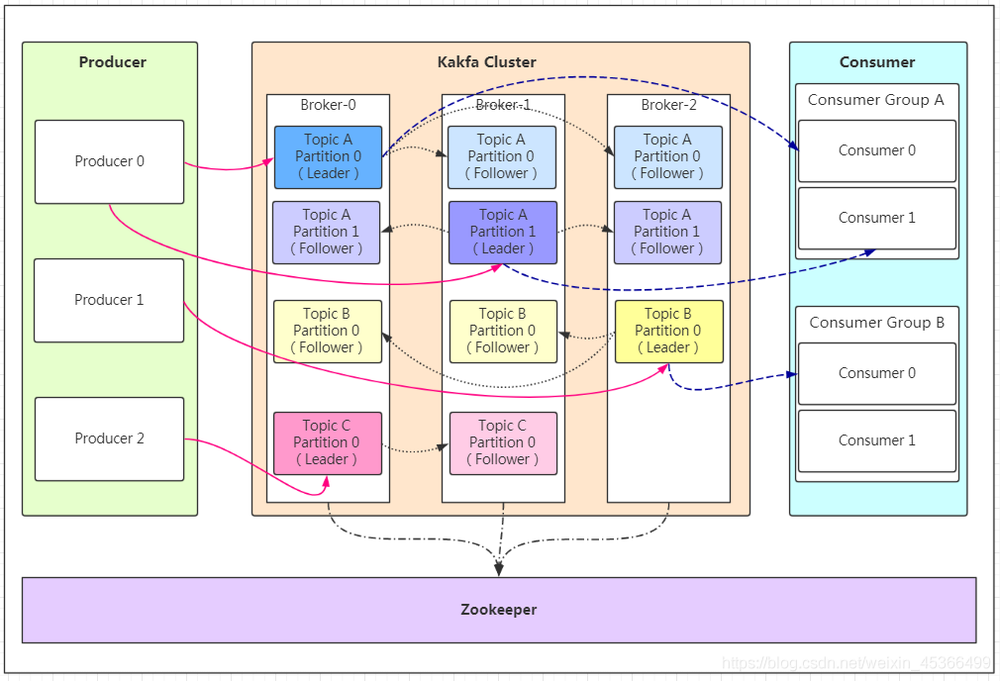
- Broker:一个 Kafka 服务端节点。
- 集群(Cluster):由多个 Broker 组成的集合。
- 消息(Message):也叫 Record,Kafka 中信息传递的载体。消息可以是网站的页面访问、服务器的日志,也可以是和 CPU、内存相关的系统资源信息,但对于消息队列 Kafka 版,消息就是一个字节数组。
- Producer:向 Kafka 发送消息的应用。
- Consumer:从 Kafka 接收消息的应用。
消费者组(Consumer Group):一组具有相同 Group ID 的 Consumer。当一个 Topic 被同一个 Group 的多个 Consumer 消费时,每一条消息都只会被投递到一个 Consumer,实现消费的负载均衡。通过 Group,您可以确保一个 Topic 的消息被并行消费,提高 Kafka 的吞吐量。 - 主题(Topic):消息的主题,用于分类消息。在每个 Broker 上都可以创建多个 Topic。
- 副本(Replica):每一个分区都有多个副本。当主分区(Leader)故障的时候会选择一个备分区(Follower)上位,成为 Leader。在 Kafka 中默认副本的最大数量是 10 个,且副本的数量不能大于 Broker 的数量,Follower 和 Leader 是在不同的机器,同一机器对同一个分区也只可能存放一个副本。
- 分区(Partition):一个有序不变的消息序列,用于存储消息。一个 Topic 由一个或多个分区组成,每个分区中的消息存储于一个或多个 Broker 上。在一个分区中消息的顺序就是 Producer 发送消息的顺序。
- 位点(Offset):分区中每条消息的位置信息,是一个单调递增且不变的值。
- 消费位点:分区被当前 Consumer 消费了的消息的最大位点。
- 堆积量:当前分区下的消息堆积总量,即最大位点减去消费位点的值。堆积量是一个关键指标,如果发现堆积量较大,则 Consumer 可能产生了阻塞,或者消费速度跟不上生产速度。此时需要分析 Consumer 的运行状况,尽力提升消费速度。可以清除所有堆积消息,从最大位点开始消费,或按时间点进行位点重置。
- 重平衡(Rebalance):消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
- Zookeeper:Kafka 集群依赖 Zookeeper 来保存集群的的元信息,以保证系统的可用性。
Kafka监控指标参考
结合 Kafka 的体系架构和使用场景,我们从 Metrics 采集、监控大盘、告警指标等3方面定义了 Kafka Metric 监控的参考模型。
Metrics 采集
1. Producer指标

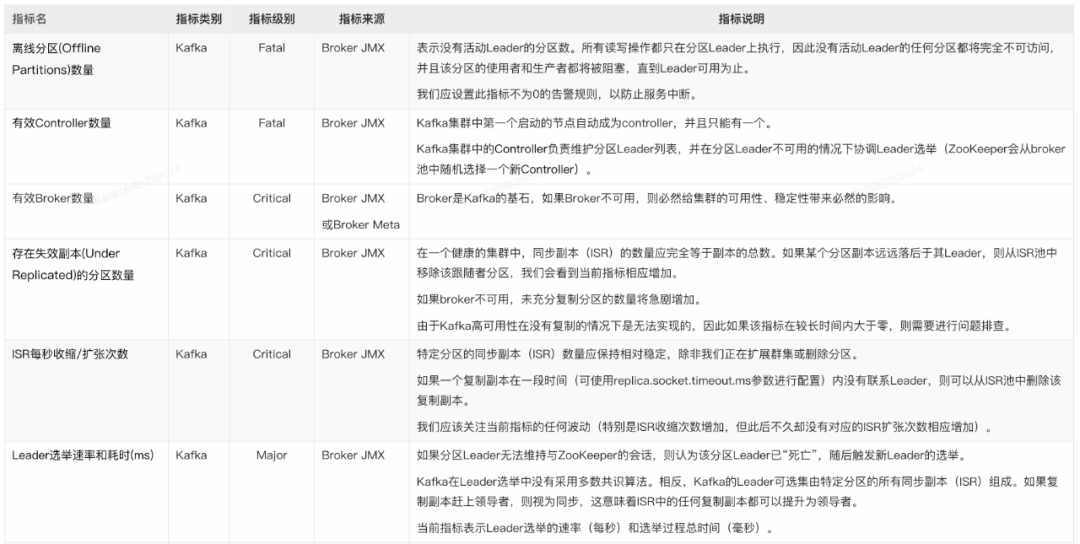
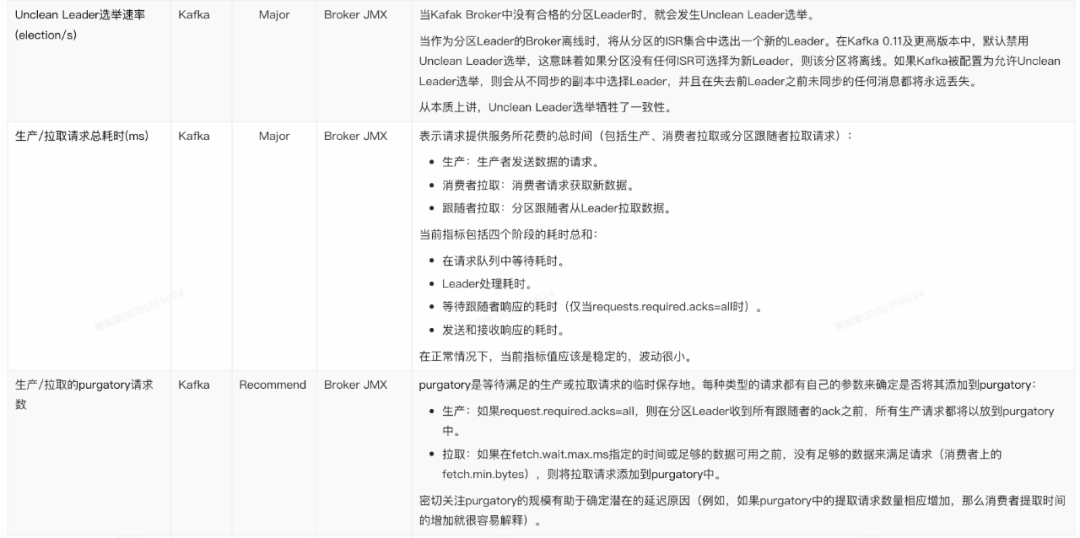
2. Broder指标

3. Consumer指标

4. Zookeeper指标
Kafka监控大盘
1. Producer
- topic 消息生产量随时间的变化:便于我们快速确定流量来源,并为基础设施的变更配置提供依据。
- 请求/响应速率随时间的变化:密切关注峰值和下降对于确保连续服务可用性至关重要。
- 请求平均延迟随时间的变化:由于延迟与吞吐量有很强的相关性,观察此变化,有助于我们判断是否需要修改 batch.size 参数。
- IO 等待随时间的变化:如果我们发现等待时间过长,就意味着生产者无法足够快地获取所需的数据。
2. Broker
- 存在失效副本的分区数量的变化:如果此指标突增,则很可能某个 Broker 发生了异常。
- ISR 数量变化:除 Broker 或 Partition 数量变化会触发 ISR 数量变化外,其它情况下的当前指标变化都需要我们注意。
- 有效 Broker 数量变化。
- 有效 Controller 数量变化。
- 离线分区数的变化:此指标大于 0,则意味着这些数量的分区不可用,该分区的消费者和生产者都将被阻塞。
- Leader 选举速率和耗时的变化:发生选举,则意味着某个 Leader 的丢失;耗时过长,则会导致此期间消息无法接收生产者消息和消费者的请求。
- 请求耗时:通常该值应相当稳定,波动很小。
- 网络流量:提供潜在瓶颈所在位置的信息,为我们判断是否启用消息的端到端压缩提供依据。
- 生产/拉取 purgatory 消息数量:通过观察 purgatory 中消息数量,有助于我们确定消息生产或拉取耗时长的原因。
3. Broker JVM
Full GC 频率和耗时:GC 频率高或耗时长,都对 Broker 性能有重大影响。据此,我们可以判断是否需要对内存进行扩容。
4. Consumer
- group 消费延迟数量的变化:该指标越大,则消息堆积越多。
- 消费流量的变化:显示消费消息的网络流量/消息流量大小变化。
- 拉取数据速率的变化:消费者是否健康的重要指标。
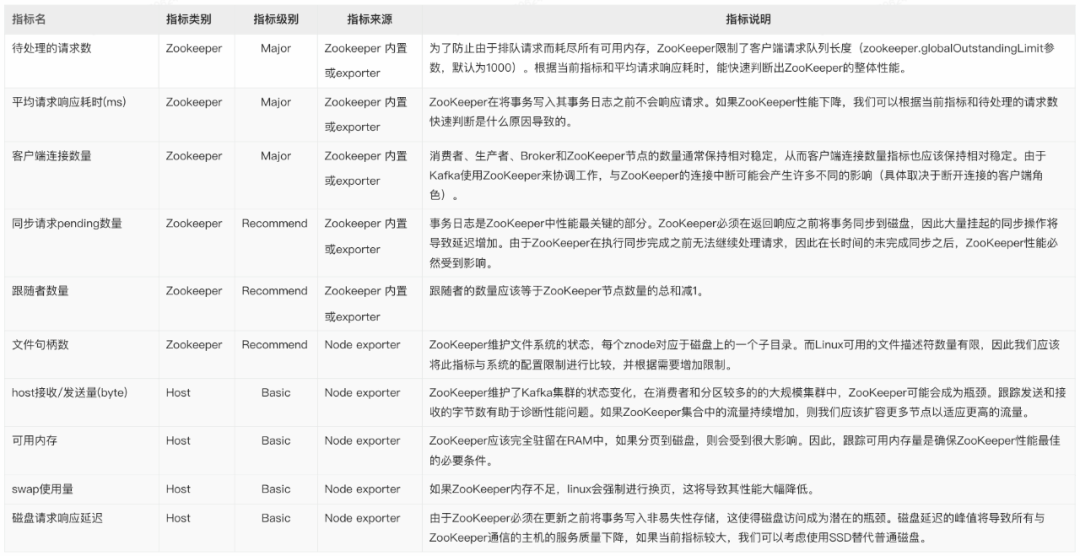
5. Zookeeper
- 待处理的请求数的变化。
- 平均请求响应耗时的变化:如果耗时突增,则可能导致整个 Kafka 集群的协调机制受阻。
- 客户端连接数的变化:连接数的突变,通常伴随着 Broker 的加入、退出或丢失。
- 打开的文件句柄数和剩余数的变化:如果剩余数不足,则可能导致 Broker 无法连接到 Zookeeper。
- 同步请求 pending 数量的变化。
Kafka 告警规则
1. Producer
- 发送失败消息数:当前发送失败的消息达到一定数量时告警。
- 发送重试消息数:当单位时间内发送重试的消息数量达到阀值时告警。
- 发送耗时长:发送耗时大于 x 毫秒。
2. Broker
- Controller 正常:有效 Controller 数量不为 1。
- 无离线分区:离线分区数大于 0。
- 无 UnClean Leader 选举:Unclean Leader 选举速率大于 0。
- Broker 不可用:有效 Broker 数量减少。
- ISR 收缩:Topic 分区的 ISR 数量小于 n。
- 分区不可用:Topic 分区处于 Under Replicated 状态。
- Topic/分区容量:Topic/分区数量大于 n。
- 实例消息流入/出量:当前实例的流量超过或低于某个阀值时告警。
- Topic 消息流入/出量:当前某个 Topic 的流量超过或低于指定阀值时告警。
- 磁盘容量:磁盘使用率大于 x%(参考值:85%)。
- CPU 使用率:大于 80%。
3. Broker JVM
FullGC 频率:对频繁的 FGC 告警。
4. Consumer
消息堆积:group 消费延迟数量大于 n(根据业务流量,适当配置 n 的大小)。
5. Zookeeper
同步请求pending数量大于n。
Kafka典型问题场景及其排查/解决方法
1. Topic消息发送慢,并发性能低
现象:某个或某几个Topic的消息并发性能低。在指标上直接体现为Producer的平均请求延迟大、平均生产吞吐量小。
问题原因:
- 网络带宽不足,导致IO等待。
- 消息未压缩,导致网络流量超负荷。
- 消息未批量发送,或批量阈值配置不当,导致发送速率慢。
- Topic分区数量不足,导致Broker接收消息积压。
- Broker磁盘性能低,导致磁盘同步慢。
- Broker分区数量过多,导致碎片化,度盘读写过载。
排查/解决方法:
- 确认 Producer 的“平均 I/O 等待时间”指标是否符合预期或有陡增?以便确认 Producer 到 Broker 之间的网络带宽是否满足业务流量要求?如果不满足,则需要硬件资源扩容。
- 确认 Producer 的“平均压缩率指标”,确保压缩率符合预期?如果压缩过低,则需要 Producer 端进行排查、修正。
- 确认 Producer 的“平均请求包大小”是否过小?如果是的话,则需要考虑加大 Producer 发送消息的 batchsize,同时调整 linger.ms 的阀值,以避免请求消息碎片化。
- 查看 Topic 分区数,分区数较小时,考虑增加分区数,以水平扩展 Broker 的并发接收消息容量。
- 确认 Broker 磁盘 IO 使用率是否在安全范围内?如果使用率已经较高,则考虑水平扩容 Broker 数量以分担磁盘压力,或升级磁盘为 SSD 以提升 IO 性能。
- 确认 Broker 的 CPU 使用率是否在安全范围内?如果使用率已经较高,则考虑垂直或水平扩容 Broker,同时考虑增加 Topic 分区数,以提升 Topic 并发接收消息能力。
- 查看集群的总分区数和单个 Broker 的分区数量,确保在规划的容量范围内。否则应考虑水平扩容 Broker 数量,以避免碎片化磁盘读写导致的性能下降。
2. Topic消息积压
现象:某个或某几个 Topic 的消息堆积持续增加。在指标上直接体现为 group 消费延迟数量持续增加。
问题原因:
- Producer生产消息流量增大。
- Consumer由于业务变化导致消费延迟增加。
- Consumer数量不足。
- Consumer数量频繁变化导致Group不断在做重平衡(Rebalance)。
- Broker未收到Consumer消费确认消息。
解决方法:
- 确认 Producer 的“消息生产量”指标是否有明显增加?如果有显示增加,则我们需要对应增加消费者数量。
- 确认 Consumer 的“消息消费流量”指标是否明显下降?如果有显示下降,则说明消费者的业务处理耗时增加,我们需要确认业务消耗,或增加消费者数量。
- 通过 Kafka Broker 提供的命令,确认 Topic 对应的 Consumer 数量与实际的 Consumer 数量是否一致?如果不一致,则说明某些 Consumer 未正确连接到 Broker,需要排查 Consumer 是否正常运行。
- 观察 Consumer 的数量是否频繁变化而触发反复再平衡(Rebalance),如果是,则我们需要排查确认各个 Consumer 是否正常运行。
- 由于网络或其它原因,可能导致 Consumer 与 Broker 之间的连接不稳定,Consumer 能持续消费消息,但 Broker 却始终认为消息未确认,导致消费位点不变。此时可能需要确认 Consumer 与 Broker 之间的网络稳定性、甚至重启 Consumer。
3. 自建Prometheus监控Kafka的痛点
- 由于安全、组织管理等因素,用户业务通常部署在多个相互隔离的 VPC,需要在多个 VPC 内都重复、独立部署 Prometheus,导致部署和运维成本高。
- 每套完整的自建观测系统都需要安装并配置 Prometheus、Grafana、AlertManager 等,过程复杂、实施周期长。
- 开源 Kafka JMX Agent 在某些场景下占用 CPU 高,对自建 Kafka 业务有一定干扰。
- 对于阿里云消息队列 Kafka 版(简称阿里云 Kafka),自建 Prometheus 无法监控到,导致无法实现一站式、全局视角的监控建设。
- 对于部署在 ECS 上的自建 Kafka,自建 Prometheus 缺少与阿里云 ECS 无缝集成的服务发现(ServiceDiscovery)机制,无法根据 ECS 标签来灵活定义抓取 targets。如果自行实现类似功能,则需要使用 GOlang 语言开发代码(调用阿里云 ECS POP 接口)、集成进开源 Prometheus 代码、编译打包后部署,实现门槛高、过程复杂、版本升级困难。
- 开源 Grafana Kafka 大盘不够专业,缺少结合 Kafka 原理/特征和最佳实践进行深入优化。
- 缺少 Kafka 告警指标模板,需要用户自行研究、配置告警规则,工作量大,且很可能缺少 Kafka 领域的专业技术沉淀。